








- Home
-

- Blog
-
- How to Guide Blogs
-
- What Is A Robots.txt File & Why Is It Important
What Is A Robots.txt File & Why Is It Important

What is a robots.txt file?
A robots.txt file is a text file that resides on a web server and contains information about which search engine crawlers should not access directories or files on the server. This file can also be used to specify how often a crawler should visit a given URL.
Key Takeaways
-
Robots.txt is a file that tells search engines which parts of your site to crawl and which to ignore
-
Useful for blocking access to duplicate content, admin pages, or files that don’t need indexing
-
Proper structure includes defining user-agents (like Googlebot), disallowed paths, and linking to your XML sitemap
-
Helps preserve crawl budget by focusing search engine attention on your most important content
-
Mistakes like blocking entire directories or essential scripts can negatively impact SEO and page rendering
-
Regular testing through tools like Google Search Console ensures your robots.txt is working as intended
So, what should go in a robots.txt file? These files contain the directives and permissions for search engines, meaning you can control the search crawling of your site. Because of this, you’ll need an experienced SEO agency to help keep everything organised and efficient.
What a robots.txt file is used for
Imagine you’ve got your awesome website up and running. Now, there are these little digital explorers, we call them web robots or crawlers, that wander around the internet, checking out different websites. Many of these are the good guys, like the ones that help Google and other search engines find and list your brilliant content so people can discover you.
A robots.txt file is like putting up a friendly little signpost on your digital doorstep. It’s a way of politely telling these web robots which parts of your website they’re welcome to explore and which areas you’d rather they didn’t visit.
Think of it this way: you wouldn’t necessarily want someone wandering through your website’s backstage areas, right? Places like the login pages for your administrators or maybe some of the internal files that keep everything ticking over. The robots.txt file lets you say, “Hey there, friendly crawler, you can have a good look around the main showroom (your public pages), but maybe steer clear of the back office (those admin areas).”
This is super handy for a few reasons. For starters, you might have some pages with similar content, and you wouldn’t want search engines to get confused or think you’re trying to game the system. By gently guiding them away from the duplicates, you help them focus on the best version of your information.
It also helps keep things tidy. Search engines have a certain amount of “energy” they can spend crawling your site. By telling them which pages are less important for them to see, you can make sure they spend their time and effort on the stuff that really matters – the content you want people to find.
Plus, sometimes you have files, like specific images or documents, that you don’t necessarily want showing up in search results on their own. The robots.txt file gives you a way to say, “Thanks, but no thanks” to the robots indexing those particular bits and pieces.
Now, it’s worth remembering that this robots.txt file is more like a friendly request than a strict rule. Most well-behaved search engine robots will happily follow your instructions. However, there might be some less scrupulous robots out there that don’t pay attention. So, while it’s a great way to manage how the good guys interact with your site, it’s not a foolproof security measure for truly private information.
You can usually find this robots.txt file by adding /robots.txt to the end of your website’s address (like yourwebsite.com.au/robots.txt). If it’s there, you can even have a peek at what instructions the website owner has put in place.
So, in plain language, a robots.txt file is your way of having a chat with the helpful web robots, guiding them around your website so they focus on the important stuff and leave the behind-the-scenes bits alone. It’s all about helping them – and ultimately, the people searching for your awesome content – have a smoother experience.
How To Create a robots.txt file:
When creating a robots.txt file, you first need to specify which user-agents are allowed to crawl your site. A user-agent in the robots file is simply the name of the software that is used to access your site, such as Googlebot or Bingbot. You can allow all user-agents to crawl your site by using an asterisk (*), or you can be more specific and only allow certain user-agents — so you could potentially have your robots.txt disallow all except Googlebot or Bingbot.
The next thing you need to do is specify which directories or files you want to block. This is done by using the “Disallow” command, followed by the path of the directory or file you want to block. You can block multiple items by using multiple Disallow lines.
Finally, you can specify how often you want a crawler to visit a given URL by using the “Crawl-delay” command. This is useful if you have a large website or know that your site will be updated frequently. By specifying a crawl delay, you can ensure that the crawlers don’t overload your server and that they have enough time to index your new content.
How to test a robots.txt file
Alright, so you’ve gone and set up a robots.txt file for your website. Now, the big question is: how do you know if it’s actually doing what it’s supposed to? How do you make sure those helpful web robots are getting the right directions? It’s a fair dinkum question!
Think of it like this: you’ve put up some signs to guide visitors around your digital property. You’d want to double-check if those signs are clear, pointing the right way, and easy for everyone to understand, wouldn’t you? Testing your robots.txt file is kind of the same thing.
One of the best ways to see if your robots.txt is working as it should is by using a special tool that Google provides. If you’ve got your website set up with Google Search Console (and it’s a ripper tool for any website owner!), you can find a section specifically for testing your robots.txt file. Inside Search Console, you’ll want to look around the “Coverage” area, and you should find something called “robots.txt Tester.” This tool lets you see exactly what your robots.txt file looks like to Google.
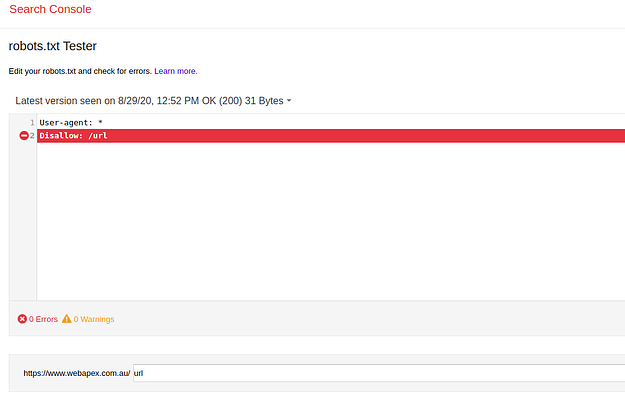
The really clever bit about this Google tool is that you can actually try out specific web addresses from your site. You can say, “Hey Google robot, would you be allowed to visit this particular page?” and the tool will tell you whether your robots.txt file is saying “Yep, come on in!” or “Nah, not this one, mate.” This is super handy for checking if you’ve successfully blocked access to those private admin areas or if you’re letting the robots see all the important content you want people to find.
Another way to get a basic understanding of your robots.txt file is simply to take a look at it yourself. Just open up your usual web browser and type in your website’s address followed by /robots.txt. So, if your website is www.yoursite.com.au, you’d type in www.yoursite.com.au/robots.txt and hit enter. What you should see is a page with plain text – that’s your robots.txt file. Give it a read-through and see if the instructions you meant to put there are actually showing up, and that there aren’t any obvious spelling mistakes or anything out of place.
While just looking at the file doesn’t tell you for sure if the robots are following the rules, it’s a good first step to make sure the sign is even there and saying roughly what you expect it to say.
There are also some other websites out there that offer tools to analyse your robots.txt file. You can usually just pop in your website’s address, and they’ll have a look at your robots.txt and might point out any potential problems or things that don’t look quite right. If you decide to use one of these, just be mindful of sharing your website’s information with another site.
When you’re testing, keep an eye out for things like spelling errors – even a tiny mistake can change the meaning of your instructions. Also, double-check that the specific pages or sections you want to block are actually listed under the “Disallow:” part, and that the important stuff you want the robots to see isn’t accidentally blocked.
Using these methods, especially the Google Search Console tool, will give you a pretty good idea of whether your robots.txt file is set up correctly and guiding those web robots the way you intend. It’s a good idea to give it a test run whenever you make significant changes to your website to make sure everything’s still pointing in the right direction.
Why a robots.txt file is important
The robots.txt file is one of the most important files on a website, as it’s the first place Googlebot will go once it reaches your site and it lets search engines know what they can and cannot crawl on your site. It should also be the place Google can find your XML sitemap.
However, it’s also one of the easiest files to get wrong, as many rules and guidelines need to be followed for it to be effective. This is why professional services are essential.
Effectively utilising a robots.txt file can help manage the limited crawl budget that Google has, and make sure all of your most important pages are indexed and discoverable.
How a robots file helps SEO
So, you’re wondering how a simple text file can help your website get found more easily on places like Google, eh? It’s a good question! While robots.txt doesn’t directly tell search engines what to rank, it plays a crucial role in helping them crawl your site efficiently, and that can have a positive knock-on effect for your SEO.
Think of it like this: search engine robots have a certain amount of time and “energy” they can spend exploring your website – we sometimes call this a “crawl budget.” If they waste their time crawling pages that aren’t important for indexing (like those admin areas, duplicate content, or resource-heavy files), they might not get around to crawling all your valuable content as frequently or as thoroughly.
A well-set-up robots.txt file helps you manage this crawl budget by politely telling these robots which areas they should focus on and which ones they should steer clear of. By doing this, you’re essentially guiding them towards your best content, the stuff you really want people to find. This means the search engines are more likely to discover and index your important pages quickly and efficiently.
4 ways a robots.txt can help your SEO
- Better Indexing of Important Website Pages: By preventing crawlers from accessing less important or duplicate content, you increase the chances that your unique and valuable pages are the ones that get indexed by search engines. This means when people search for relevant terms, your best content is more likely to show up.
- Avoiding Duplicate Content Issues: If you have multiple versions of the same content (which can sometimes happen with different URLs or parameters), telling search engines which version to ignore via robots.txt can help you avoid being penalised for duplicate content. Search engines prefer to show unique and original content.
- Improved Site Speed and Performance (Indirectly): While robots.txt doesn’t directly speed up your site for users, by blocking access to resource-heavy areas or files that don’t need to be crawled, you can reduce the load on your server. This can indirectly contribute to better site performance, which is a factor search engines consider.
- Focusing Crawl Effort on Indexable Content: By disallowing things like internal search results pages, thank you pages, or staging environments, you ensure that the search engine’s crawling efforts are concentrated on the pages that actually deserve to be in the search results.
At the end of the day, robots.txt isn’t a magic SEO bullet, it’s an important foundational element. It helps you make the most of the search engine’s visit to your site, ensuring they spend their time where it matters most. By guiding the crawlers effectively, you’re helping them understand your website better, which can ultimately lead to better visibility in search results for your content. Think of it as being a good host to the search engine robots, making their visit efficient and worthwhile!
Finding your robots.txt file:
Finding and viewing your website’s robots.txt file isn’t a technical SEO nightmare — it’s actually quite straightforward.
- Robots.txt example Simply type the URL of your page and end it with /robots.txt — e.g. www.exampleURL.com.au/robotics.txt
The most basic setup for a robots file
The most fundamental setup for a robots.txt file is actually an empty file.
Yep, you heard that right! If you don’t have a robots.txt file at all, or if it’s completely blank, the assumed behaviour for most well-behaved web robots is that they are allowed to crawl and index all public parts of your website.
Think of it like this: if you don’t put up any “Keep Out” signs on your property, folks will generally assume they’re welcome to have a look around the publicly accessible areas.
So, in its most basic form, the absence of a robots.txt file, or a completely empty one, signals to the good web robots: “Hey, feel free to explore the whole place!”
Now, while an empty file is the most basic, it’s worth considering if that’s actually what you want. For most websites, even a very simple robots.txt file with at least one instruction is a good idea.
If you do want to give even a single instruction, the next most basic setup would be to disallow access to a specific area for all robots.
That would look something like this:
User-agent: *
Disallow: /some-private-directory/
In this example:
- User-agent: * means this rule applies to all web robots. The asterisk (*) is like a wildcard saying “any robot.”
- Disallow: /some-private-directory/ tells all robots not to access any files or folders within the /some-private-directory/ on your website.
Even this simple two-line setup gives you a little bit of control.
So, to summarise:
- Absolute most basic: An empty robots.txt file (or no file at all), which implies everything is allowed.
- Next level basic (with an instruction): Disallowing a specific directory for all robots, like the example above.
Keep in mind that for most websites, you’ll likely want something a little more specific than just an empty file to help manage how search engines crawl and index your content effectively. But in its purest, most stripped-back form, an empty robots.txt is the most basic setup.
What does an empty robots.txt mean?
An empty robots.txt file means the website owner doesn’t mind if search engines index their website. To decide on this, you’ll need some help to find out what you need to leave in and what you need to leave out.
What happens if you don’t use a robots.txt file
If you do not use a robots.txt file, search engines may index all of the pages on your website, including the pages you do not want them to index. This can lead to your website being penalised by search engines, and it can also cause people looking for information on your website to be unable to find it.
What ‘blocked by robots.txt’ means
‘Blocked by robots.txt’ means that a web crawler, such as Googlebot, is not permitted to crawl all or part of the page. This can be done for various reasons, including keeping the search engine from indexing duplicate content or spam on your site.
The 6 most common robots.txt mistakes and how to fix them:
Even though it’s a simple text file, it’s surprisingly easy to make a boo-boo with your robots.txt.
Here are some of the most common mistakes we see and how to get them sorted:
1. Blocking Everything:
- The Mistake: Accidentally using Disallow: / which tells all robots they’re not allowed to access any page on your site. This is like putting a giant “Closed” sign on your entire digital shopfront!
- How to Fix It: Double-check your Disallow lines. If you meant to block a specific directory, make sure the path is correct (e.g., Disallow: /admin/). If you didn’t mean to block everything, simply remove the Disallow: / line or correct it to target the intended area.
2. Typos and Syntax Errors:
- The Mistake: Little spelling mistakes in User-agent or Disallow, or incorrect formatting. Robots are pretty literal; if it’s not exactly right, they might not understand the instruction.
- How to Fix It: Carefully review your robots.txt file for any typos. Ensure that User-agent: and Disallow: are spelled correctly and that there’s a space after the colon. Use the Google Search Console’s robots.txt Tester – it’s brilliant for highlighting syntax errors.
3. Blocking Important Content:
- The Mistake: Accidentally disallowing access to crucial parts of your website that you want search engines to crawl and index, like your product pages, blog posts, or homepage.
- How to Fix It: Review your Disallow rules and make sure they only target non-essential areas. If you find you’ve blocked something important, remove the corresponding Disallow: line.
4. Forgetting the Trailing Slash:
- The Mistake: Sometimes, whether you include a trailing slash (/) at the end of a directory in your Disallow rule can matter. For example, Disallow: /blog might be interpreted differently from Disallow: /blog/ by some robots.
- How to Fix It: Be consistent with your use of trailing slashes. Generally, it’s a good idea to include a trailing slash when referring to a directory. Test your rules in Google Search Console to see how they are being interpreted.
5. Using Allow: Incorrectly (or Thinking it’s Widely Supported):
- The Mistake: While some search engines (like Google) understand the Allow: directive to specifically allow access to a subdirectory within a disallowed area, it’s not universally supported. Relying heavily on Allow: might not work as expected for all robots.
- How to Fix It: Where possible, structure your disallowed rules to be more specific rather than relying on Allow:. For example, instead of disallowing /folder/ and then allowing /folder/subfolder/, you might only disallow specific content within /folder/. Always test with the Google Search Console tool to see how Google interprets your Allow: rules.
6. Blocking CSS and JavaScript Files:
- The Mistake: Accidentally disallowing access to your website’s CSS (styling) and JavaScript (interactive elements) files. This can prevent search engines from rendering your pages correctly, potentially affecting how they understand and rank your content.
- How to Fix It: Generally, you should allow search engines to access your CSS and JavaScript files so they can see your website as a user would. Remove any Disallow: rules that are blocking these file types or the directories they are in (like /css/ or /js/).
7. Not Having a robots.txt File at All (When You Need One):
- The Mistake: Simply not having a robots.txt file when you have sections of your site you’d prefer search engines not to crawl.
- How to Fix It: Create a robots.txt file and place it in the root directory of your website (e.g., yourwebsite.com.au/robots.txt). Include the necessary Disallow: rules for the areas you want to block.
2 Easy Ways to Check for Mistakes in a Robots file:
- 1.Google Search Console’s robots.txt Tester: As mentioned before, this is your best friend for identifying syntax errors and testing specific URLs.
- 2.Manual Review: Regularly take a look at your robots.txt file to ensure it still reflects your desired crawling rules, especially after making changes to your website structure.
Closing thoughts:
Do your best to be aware of these common pitfalls and use the available testing tools frequently. We understand that technical SEO can be the hardest area of SEO to get right, unless you do it daily and run 100’s of site audits like we do! Robots.txt file maintenance and management is just one of the many things we deliver that make us Australia’s leading SEO agency. Get in touch with our top notch digital marketing team today and see how we can help you!

About the Author
Andrew Raso
Share




